
鬼网!

GhostNet产生原因
mobileNet或者是shuffleNet提出了使用depthwise或者是shuffle等操作,但是引入的1x1卷积依然会产生一定的计算量
为什么1x1卷积依然会产生较大的计算量?看卷积计算量的计算公式$n ∗ h ∗ w ∗ c ∗ k ∗ k $,可以发现,由于c和n都是比较大的,所以会导致这个计算量也是比较大的(后文具体结构复现时还会解释)
所以,我们如何在这个基础上再减少参数,优化网络速度呢,作者从一个独特的角度,观察了ResNet50第一个残差块输出的特征图,发现有许多输出特征很相似,基本只要进行简单的线性变换就能得到,而不需要进行复杂的非线性变换得到。
如图:
以上图片中同色图片可以使用cheap operations进行生成
所以可以先通过一个非线性变化得到其中一个特征图,针对这个特征图做线性变化,得到原特征图的幽灵特征图。
ps:这里说的非线性卷积操作是卷积-批归一化-非线性激活全套组合,而所谓的线性变换或者廉价操作均指普通卷积,不含批归一化和非线性激活

所以,总结其核心思想就是:设计一种分阶段的卷积计算模块,在少量的非线性的卷积得到的特征图基础上,再进行一次线性卷积,从而获取更多的特征图,而新得到的特征图,就被叫做之前特征图的‘ghost’,以此来实现消除冗余特征(也可以说是不避免冗余的特征映射,而是使用一种更低成本效益的方式接受它),使得在保持相似的识别性能的同时,降低通用卷积层的计算代价,以获取更加轻量的模型(非线性的操作是 昂贵的,线性操作是 廉价的)(这操作鬼想得到。。。)
Ghost module
鬼模块!

功能实现
图例:(解释Ghost module的大致功能)
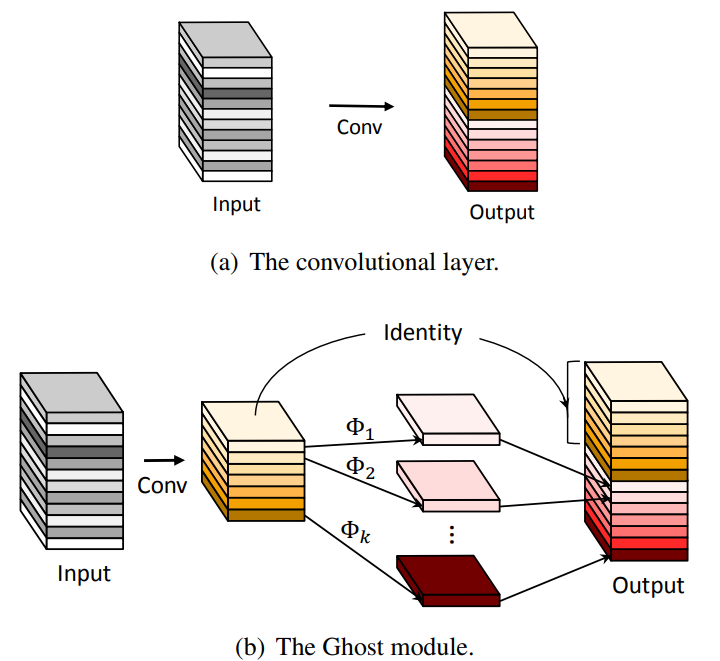
如图所示,相较于传统卷积,直接对input进行卷积操作(昂贵的非线性运算),Ghostnet则先进行部分卷积,得到channel较少的特征图,之后再使用这些特征图cheap operation进行廉价的线性运算,得到更多的特征图,最后将不同的特征图concat到一起,组合形成新的output
计算
首先,假设我们输入特征图的尺寸是 ,输出特征图的尺寸是 ,卷积核大小为
在cheap operation变换中,我们假设特征图的channel是 m,变换的数量 s 代表这m个通道分别被线性映射几次,最终得到的新的特征图的数量是n,那么我们可以得到等式:
由于Ghost的变换过程中最后存在一个恒等变换(Identity——直接将第一步conv生成的特征图作为output的一部分,该过程也属于线性映射),所以实际有效,生成新特征图的变换数量是s-1,所以上式可以得到如下公式:
可以看出,ghostnet对m个通道进行分别的卷积,所以使得Ghost模块中的线性映射具有很大的多样性
以论文中的公式复现ghostnet module实现过程
对于输入数据 ,卷积层操作如公式1, ,为输出的n维特征图, 为该层的卷积核 ,所以该层的计算量为 这个数据量通常成千上万,因为c(输入图片数)和n(输出特征图数)通常会很大 。公式1的参数量与输入和输出的特征图数息息相关,而从图1可以看出中间特征图存在大量冗余,且存在相似的特征(Ghost),所以完全没必要占用大量计算量来计算这些Ghost
假设原输出的特征为某些内在特征进行简单的变换得到Ghost,通常这些内在特征数量都很少,并且能通过原始卷积操作公式2获得, 为原始卷积输出, 为使用的卷积核, ,baise直接简化掉
为了获得原来的维特征,对 的内在特征分别使用一系列简单线性操作来产生维 ghost 特征,为生成的 ghost特征图的线性变化函数,对每一个卷积核(特征图)进行s-1次的线性变换,最后生成s-1 + 1个特征图(原特征图加ghost特征图)
与主流卷积操作对比
- 对比Mobilenet、Squeezenet和Shufflenet中大量使用1 × 1 pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量
- 目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征
- 目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性
- Ghost模块同时使用identity mapping来保持原有特征
复杂度分析
在理想情况下 次线性运算之间可以拥有不同的形状和参数,但是在线推理会受阻,特别是考虑到cpu和gpu的使用,所以,在论文中,作者建议我们在一个ghostnet模块中使用相同大小线性操作(如3x3,5x5)以便更加有效的实现
假设Ghost模块包含1个identity mapping和 个线性变换,每个线性操作核的大小为
以下是ghostnet模块计算量的压缩比例和参数量的压缩比例:(在此处, 与 有着相似的大小,是第一次变化时的输出通道数目)
where has the similar magnitude as that of , and . Similarly, the compression ratio can be calculated as
式子4为理论的加速比公式 ,可以看出相较于普通的卷积,ghostnet的压缩比例都是s,且$s<< c $ 所以,可以看出ghostnet的计算量缩减基于自己定义的s参数,且自定义的s一般远小于c
式子5为理论的压缩比公式,该式子是利用刚刚提出的Ghost module加速比而生成的
Ghost Bottlenecks
鬼脖子!

功能实现
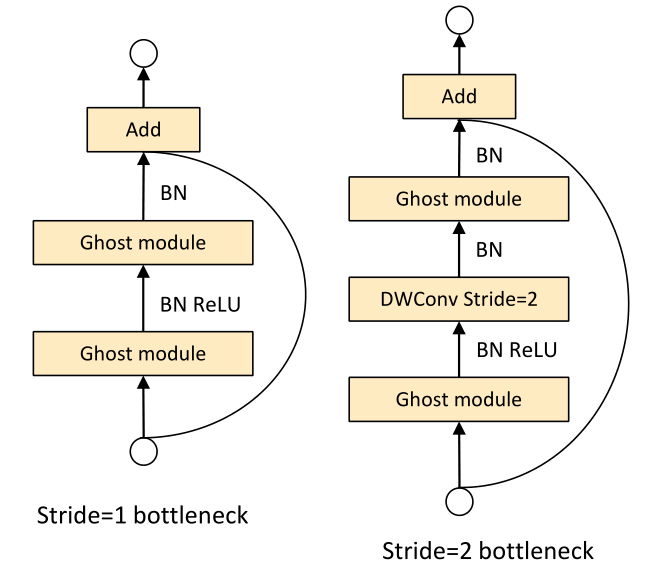
Ghost Bottleneck(G-bneck)与residual block类似,主要是两个Ghost模块堆叠二次形成,先升维后降维而不是常见的先降维后升维
第一个模块作为一个扩展层,增加了通道的数量(增加特征维度),我们将输出通道数与输入通道数的比值(增大的比例)称为扩展比 / expansion ration,
而第二个模块减少了与快捷路径匹配的通道数量(减少特征维度 / 通道数),使其与shortcut一致,然后与输入相加,
之后在这两个Ghost模块的输入和输出之间连接快捷方式。每一层后应用批处理标准化(BN)和ReLU非线性处理,除了没有在第二个Ghost模块后使用ReLU其他都使用了Relu处理,
G-bneck包含stride=1和stride=2版本,对于stride=2,shortcut路径使用下采样层,并在Ghost模块中间插入stride=2的深度(depthwise)卷积
在实际使用中,为了加速提高效率,两个Ghost模块之间插入的是点(pointwise)卷积
GhostNet 组成
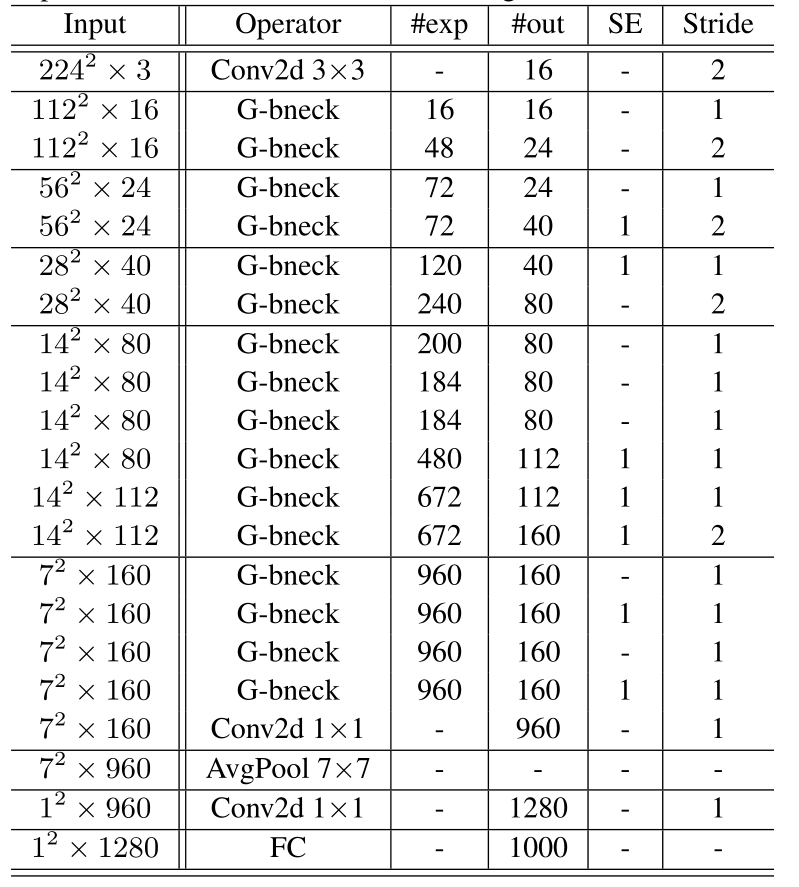
G-bneck表示Ghost Bottleneck。#exp表示扩展大小。#out表示输出通道的数量。SE表示是否使用SE模块
分析:
基于MobileNetV3的架构优势,使用Ghost Bottleneck取代了MobileNetV3中的Bottleneck。GhostNet主要由Ghost Bottleneck组成,以Ghost module作为构建块。第一层是标准的卷积层,有16个滤波器,然后是一系列Ghost瓶颈,通道逐渐增加。根据输入特性映射的大小,这些Ghost Bottleneck被分为不同的阶段。所有Ghost Bottleneck都是在stride=1的情况下应用的,除了每个阶段的最后一个Bottleneck是stride=2。最后利用全局平均池化和卷积层将特征映射转换为1280维的特征向量进行最终分类。挤压和激励(SE)模块也应用于一些重影瓶颈中的残余层,如图,相对于MobileNetV3,我们不使用hard-swish 函数(因为其高延迟)。该体系结构提供了一个基本的设计参考,但进一步的超参数调整或基于Ghost module的自动体系结构搜索,以进一步提高性能。
Width Multiplier
即使上图中的GhostNet结构已经很高效,但在某些特定场景下仍然需要需要对模型进行调整,可以简单地使用α对每层的维度进行扩缩(在每一层的通道上都乘一个因子),被称为width multiplier,使用α的GhostNet表示为GhostNet-α×。模型大小与计算量大约为倍,通常,较小的α导致较低的延迟和较低的性能,反之亦然。
我的想法:
GhostNet减少了参数量,会生成的相似特征图,(或许)可以达到更强的泛化性,但是精度还是会有所下降
既然在ghostnet中精度会下降,那如果使用自带的α(宽度因子)且(α>1)是否可以做到保持甚至提高性能的同时降低延迟
本身GhostNet是会降低延迟的,而放弃一点降低效果,之后调大宽度因子,或许可以达到这个效果呢
GhostNet——Experiments
超参数分析
Ghost模块有两个超参数,分别是上面说的s,产生m=n/s固有特征图以及参数d,线性映射中的卷积核dxd的大小。
这两个参数的影响,是在VGG16的基础上进行实验的。
首先固定s=2,然后测试d={1,3,5,7},图6表3的结果是网络在CIFAR-10上的表现,可以看出d=3的表现最好,这是因为1x1的卷积核无法在特征图上引入空间信息,而d为5或者是7导致了过拟合核更大的计算量,因此,作者采取d=3来进行接下来的有效性和效率的实验。
接下来是固定d=3,然后测试s={2,3,4,5}。实际上,s直接关系到计算量和网络的表现,因为大的s导致了更大的压缩和加速比例,结果显示,当增加s时,无论是速度还是准确率都出现下降,当s为2时,代表着VGG16被压缩了两倍,作者提出的方法表现比VGG16还要好一点,体现出Ghost模块的优越性。
与SOTA对比
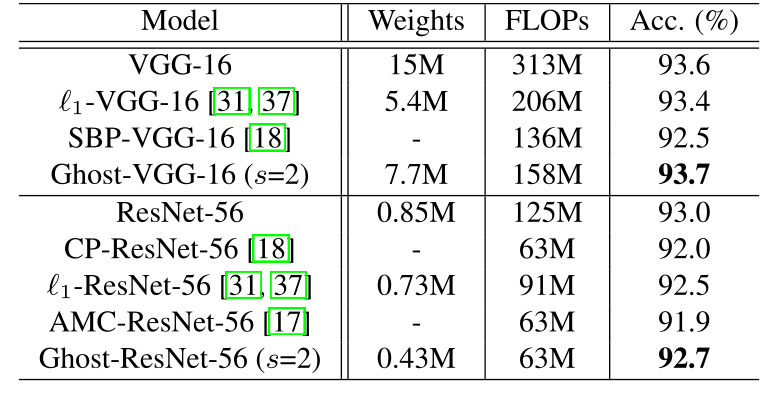
作者将VGG16和ResNet56与SOTA的压缩模型在CIFAR10数据集上进行对比,作者的模型可以在达到更高的准确率的同时,减少网络的推理速度
将Ghost生成的特征图可视化

尽管生成的特征图都是基于同一个特征图产生的,但是它们之间确实有很大的不同,如图。这意味着生成的特征更加的灵活多变,可以满足特定任务的需求。(这里可以看出Ghost其实使得同一个特征图中不同通道包含了不同的特征信息,增强了模型的表现力)。
ImageNet上的分类表现
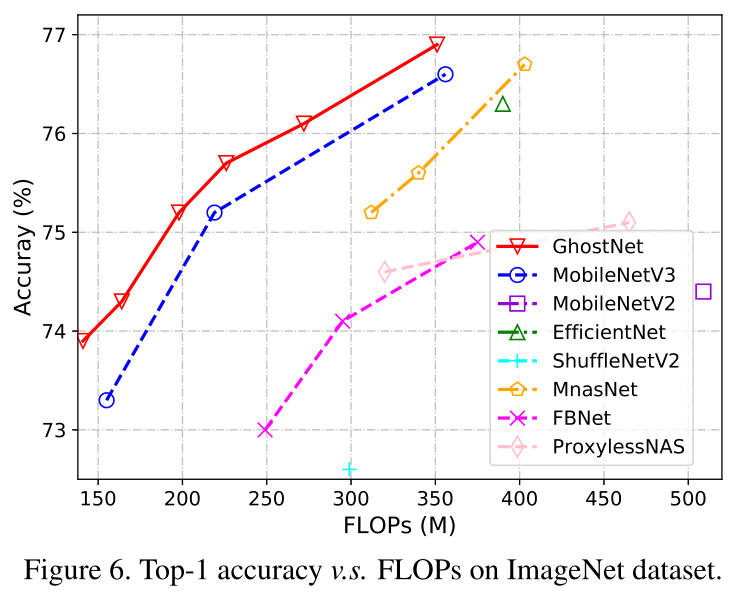
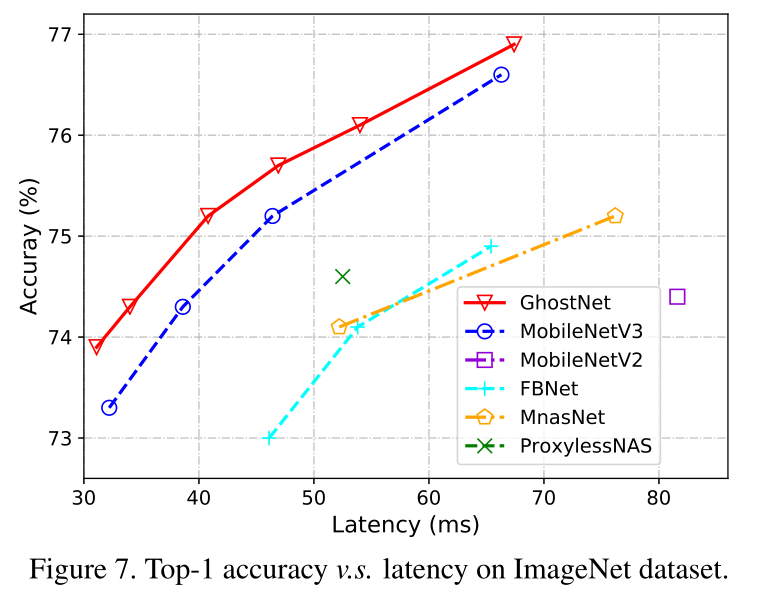

使用k = 1,s = 2 ,d = 3 的GhostNet,不同的模型大小使用不同的α值进行调整
作者按照FLOPs的数量级将图7中的表格分为了四类,例如~50,~150,200-300等。从结果中我们可以看到,通常较大的FLOP在这些小型网络中会导致更高的准确性,这表明了它们的有效性。整体而言,GhostNet最轻量且准确率最高,在各种计算复杂度级别上始终优于其他的对比网络,因为GhostNet在利用计算资源生成特征图方面更加有效。
目标检测
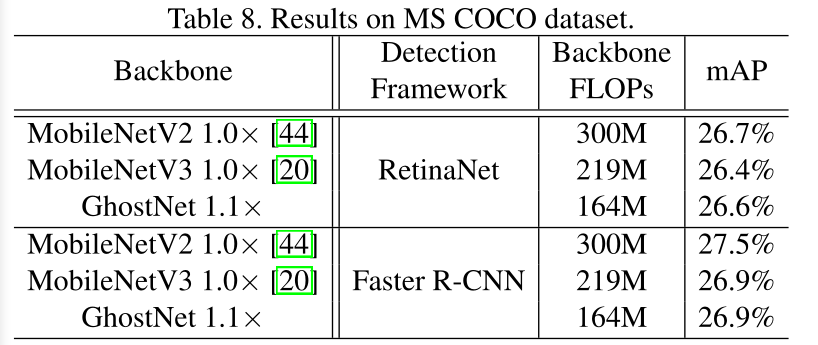
在one-stage和two-stage检测算法上,GhostNet能降低大部分计算量,而mAP与其它主干网络差不多
为了进一步评估GhostNet的泛化能力,作者在MS COCO数据集上进行了目标检测实验。 作者将拆分出来的trainval35k作为训练数据,以mAP作为评价的指标。作者采用了 具有特征金字塔网络(FPN)的两阶段Faster R-CNN 和一阶段的RetinaNet 来作为实验的框架,而GhostNet被用来作为特征提取器。 作者使用的预训练模型是在ImageNet上使用SGD训练12个epochs的模型,将输入图像的大小调整为800的短边和不超过1333的长边。 上图展示了检测结果,其中FLOP是使用224×224尺寸的输入图像计算出来的。实验结果表明GhostNet大大降低了计算成本,无论在RetinaNet还是在Faster R-CNN框架上,都可以达到与MobileNetV2和MobileNetV3相同水准的mAP
Conclusion
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,值得学习。
附言
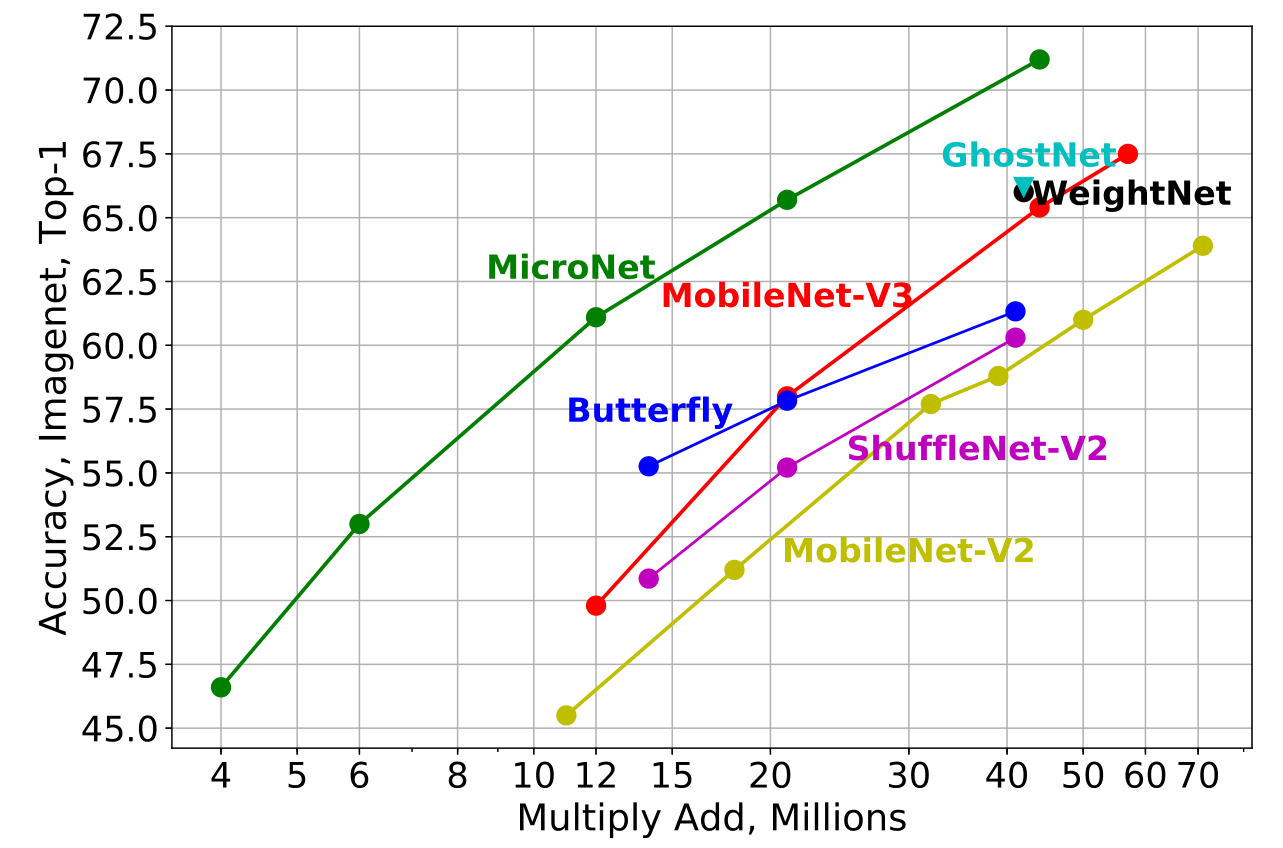
还有一个很强大的轻量级主干网络,其效果极强,比ghostnet强,只是没有开源,名为MicroNet
鬼鬼!
鬼鬼!
